
Inhoud

Samen met zijn nieuwe Mali-G77 grafische processor en Mali-D77-displayprocessor heeft Arm zijn nieuwste krachtige CPU-ontwerp onthuld: de Cortex-A77. Net als bij de Cortex-A76 van vorig jaar, is de Cortex-A77 ontworpen voor eersteklas toepassingen die het kenmerkende lage stroomverbruik van Arm vereisen. Alles van smartphones tot laptops en waarschijnlijk daarbuiten.
Met de Cortex-A77 heeft Arm zich gericht op de maximale prestatieverhoging van instructies per cyclus / klok (IPC) die het zou kunnen beheren via de Cortex-A76. Klokfrequenties, stroomverbruik en gebied zijn allemaal ontworpen om ruwweg in dezelfde marge te blijven, maar de nieuwe kern kan door meer instructie tegelijk knappen. Om dit te doen, heeft Arm een nog bredere kern ontworpen dan vorig jaar en heeft een aantal verbeteringen aangebracht om de CPU-kern te voorzien van dingen om te doen. Maar voordat we daarop ingaan, gaan we eerst in op het overzicht op hoog niveau en de prestaties.
Prestatiedoelen behalen
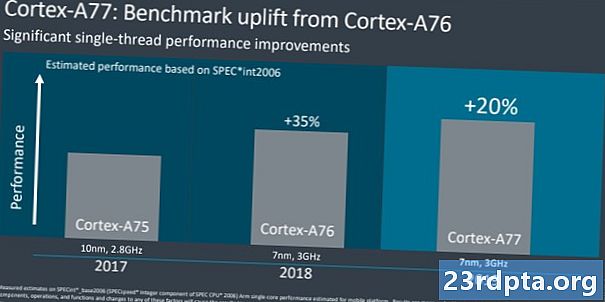
Terug in augustus 2018 deelde Arm ongewoon een CPU-routekaart tot 2020. Vanaf 2016 Cortex-A73 tot en met 2020 'Hercules'-ontwerp, belooft het bedrijf een 2,5x hogere rekenprestatie. Een behoorlijk stuk van deze enorme projectie werd bereikt met de grote microarchitectuur-verschuiving met de Cortex-A76, hogere moderne kloksnelheden en de overgang van 16 naar 10 en nu 7nm productie met 5nm om te volgen. Ongeveer 1,8x van de winst van de routekaart werd al vorig jaar behaald en de Cortex-A77 biedt een verdere IPC-boost van ongeveer 20 procent. Hiermee zijn we goed op weg naar het 2,5x-doel van Arm, hoewel mobiele apparaten met een beperkt stroom- en thermische budget niet al deze voordelen verwachten.
Ter vergelijking: de Cortex-A76 van vorig jaar gaf een boost van ongeveer 30-35 procent ten opzichte van de Cortex-A75. Dit jaar kijken we naar een meer gedempte, maar nog steeds significante, 20 procent IPC-winst tussen de A77 en de A76. Dit is goed nieuws omdat het meer prestaties betekent en zich aan dezelfde thermische en stroombeperkingen houdt als voorheen. De afweging is dat de A77 ongeveer 17 procent groter is dan de A76, dus een beetje meer kost in termen van siliciumoppervlak. Als u een vergelijking met de desktopleiders wilt, beheerde AMD een IPC-boost van 15 procent tussen Zen2 en Zen +, terwijl de IPC van Intel jarenlang vrijwel statisch is gebleven.Natuurlijk hebben we het hier over verschillende marktsegmenten, maar dit laat zien hoe het CPU-ontwerpteam van Arm de afgelopen generaties indrukwekkende winsten heeft gemaakt.
Een prestatieverbetering van 20% wordt aangeboden voor op Cortex-A77 gebaseerde SoC's van de volgende generatie
Het voordeel hiervan is dat de A76 een grote micro-architecturale verschuiving markeerde met enorme prestatiewinst, terwijl we terug zijn naar verbeteringen op het optimalisatieniveau met de A77. Met dat uit de weg, laten we duiken in wat nieuw is in de Arm Cortex-A77.
Cortex-A77 bouwt voort op de A76-microarchitectuur
De sleutel tot het begrijpen van het verschil tussen de Cortex-A77 en de A76 is om te begrijpen wat wordt bedoeld met een "breder" kernontwerp. In wezen hebben we het over de mogelijkheid om meer instructies uit te voeren voor elke klokcyclus, wat de doorvoer van de kern verhoogt. Er zijn twee belangrijke onderdelen om dit goed te doen: het aantal uitvoeringseenheden verhogen om de verwerking uit te voeren en ervoor zorgen dat deze eenheden goed worden gevoed met gegevens. Laten we beginnen met het laatste deel en ons concentreren op de delen voor verzending, cache en vertakkingsvoorspelling van de SoC.
De Cortex-A77 ziet een 50 procent boost voor de verzendbreedte, tot zes instructies per cyclus van vier met de A76. Dat betekent meer instructies op weg naar de uitvoeringskern voor elke klokcyclus voor een groter prestatiepotentieel. Het out-of-order uitvoeringsvenster is hierdoor ook groter, oplopend tot 160 items om meer parallellisme te tonen. Er is een bekende 64K instructie-cache, terwijl de Branch Target Buffer (BTB), die adressen bevat voor de branchvoorspeller, 33 procent groter is dan voorheen om de groei in parallelle instructies te verwerken. Niets ongewoons hier, het is in wezen een bredere versie van het ontwerp van vorig jaar.
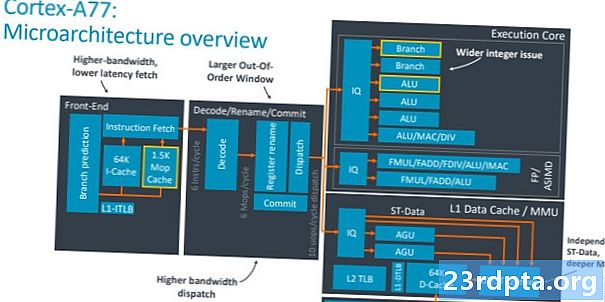
De meer intrigerende front-end toevoeging is de geheel nieuwe 1,5K MOP-cache, waarin macro-Ops (MOP's) worden opgeslagen die vanuit de decodeereenheid worden teruggekoppeld. De CPU-architectuur van Arm decodeert instructies van de toepassing van een gebruiker in kleinere macro-bewerkingen en vervolgens verder in micro-ops die de uitvoeringskern begrijpt. Je kunt dit zien in het bovenstaande diagram in de decodeersectie. De MOP-cache wordt gebruikt om de kostenboete van gemiste vertakkingen en flushes te verminderen, omdat u de macro-operaties vasthoudt in plaats van ze opnieuw te decoderen, en verhoogt de algehele doorvoer van de kern. Haal van de MOP in plaats van i-cache omzeil het decodeerstadium en bewaar één cyclus. Arm beweert dat de MOP-cache een hitpercentage van 85 procent of meer kan bereiken voor verschillende workloads, waardoor het een zeer nuttige aanvulling is op de standaard i-cache.
Let op de toevoeging van een vierde ALU en tweede Branch-eenheid naar het uitvoeringsgedeelte van de CPU. Deze vierde ALU verhoogt de algemene bandbreedte van de processor met 50 procent. Deze extra ALU is in staat tot basisinstructies met één cyclus (zoals ADD en SUB) plus bewerkingen met twee cycli met gehele getallen zoals een vermenigvuldiging. Twee van de andere ALU's kunnen alleen basisinstructies met één cyclus verwerken, terwijl de laatste eenheid wordt belast met geavanceerdere wiskundige bewerkingen zoals delen, vermenigvuldigen, accumuleren, enz. De tweede vertakkingseenheid in de uitvoeringskern verdubbelt het aantal gelijktijdige vertakkingen core kan verwerken, wat handig is in gevallen waarbij twee van de zes verzonden instructies branch-jumps zijn. Dit klinkt een beetje vreemd, maar interne tests bij Arm hebben de voordelen van het gebruik van deze tweede eenheid aangetoond.
De Cortex-A77 biedt verbeterde parallelliteit en een nieuwe kijk op pre-fetch caches
Andere aanpassingen aan de CPU-kern zijn de toevoeging van een tweede AES-coderingspijplijn. De data store-pijpleidingen hebben nu speciale uitgiftepoorten om de geheugenbandbreedte te verdubbelen. Deze poorten werden eerder gedeeld met de ALU's, die soms een knelpunt konden worden. Er is ook een gegevensgenerator van de volgende generatie om de energie-efficiëntie te verbeteren en tegelijkertijd de bandbreedte voor systeem-DRAM te vergroten.
Een deel van dit systeem in de Cortex-A77 beschikt ook over een geheel nieuw "systeembewust" prefetch-systeem. Dit verbetert de geheugenprestaties op basis van het brede scala aan CPU-kerntellingen, cachecapaciteiten en latenties en geheugensubsysteemconfiguraties in definitieve apparaten. De speciale hardware om te communiceren met de Dynamic Scheduling Unit (DSU) als onderdeel van een DynamIQ CPU-cluster, die het gebruik van de gedeelde L3-cache bewaakt. De kern heeft dynamische afstands- en agressiviteitsniveaus om het cachegebruik te verminderen in situaties waarin de L3-bandbreedte wordt beperkt door andere CPU-kernen. Kernen met hogere prestaties zoals de Cortex-A77 verzadigen eerder DSU-toegang tot geheugen, terwijl kernen met een lager vermogen zoals de A55 dat waarschijnlijk niet doen.

Alles bij elkaar passen
Er zijn veel kleine wijzigingen in de Cortex-A77 die tot een aantal substantiële verschillen ten opzichte van zijn voorganger leiden. Kortom, de nieuwe MOP-cache van de A77 in combinatie met een breder en langer instructievenster helpt de uitgebreide ALU, Branch en geheugenunits bezig te houden met dingen die er te doen zijn. Het krachtpatser Cortex-A76-ontwerp is uitgebreid om de doorvoer nog verder te verbeteren met de A77, zonder te vertrouwen op hogere kloksnelheden.
De grootste prestatieverbeteringen voor de Cortex-A77 komen aan in de vorm van een geheel getal en drijvende komma wiskunde. Dit wordt bevestigd door de interne benchmarks van Arm, die een prestatieverbetering van 20 tot 35 procent laten zien in respectievelijk SPEC-integer- en drijvende-kommabanken. Verbetering van de geheugenbandbreedte ligt ergens tussen de 15 en 20 procent, opnieuw benadrukkend dat de grootste winst komt in de vorm van nummerverwerking. Over het algemeen geven deze verbeteringen de A77 een gemiddelde stijging van 20 procent ten opzichte van de vorige generatie. Mogelijk zien we later dit jaar of begin 2020 ook wat meer, meer marginale winst als gevolg van meer geavanceerde 7nm-productieprocessen.
Wat smartphones betreft, zijn Cortex-A77-aangedreven SoC's bestemd voor hoogwaardige, vlaggenschipproducten. Arm verwacht volledig dat het krachtpatserontwerp 4 + 4 bit zal gebruiken. LITTLE kernopstellingen. Gezien de verhoogde doorvoer en de lichte toename van de oppervlakte van de A77, zullen SoC-ontwerpers waarschijnlijk de trend van 1 + 3 + 4 of 2 + 2 + 4 verder zetten. Met een of twee krachtige grote kernen met grotere caches en hogere klokken, ondersteund door 2 of 3 A77-kernen met kleinere cachegroottes en lagere klokken om te besparen op stroom en gebied. Uiteindelijk spelt de Cortex-A77 goede dingen voor smartphones en de groeiende markt voor altijd verbonden Arm-gebaseerde laptops. Let later dit jaar op aankondigingen van silicium.


")